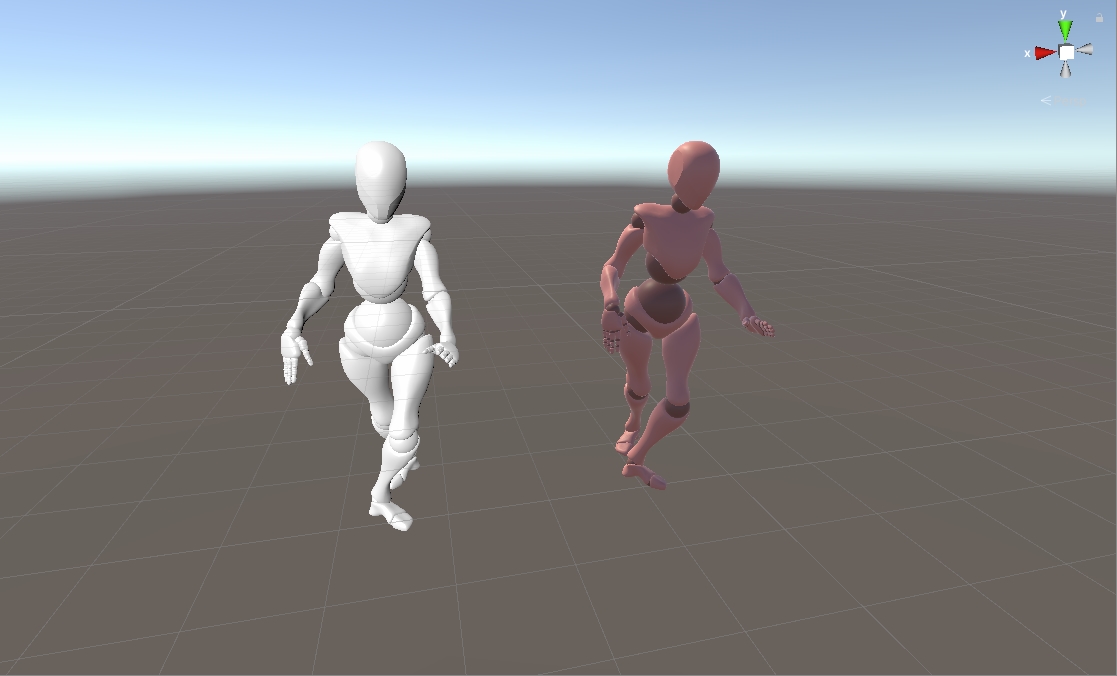
支持Animator Controller的实时GPU蒙皮
为什么要用GPU来进行蒙皮 对于一个SkinnedMeshRenderer,在做蒙皮的时候,对于每一个顶点,会先计算出这个顶点对应的四根骨骼的从骨骼空间到物体空间的矩阵\(M_{bone\localtoobject}\),然后使用\(M{bone\localtoobject} * M{bone\bindpose} * Vertex{objectspace}\)得到经过骨骼平移旋转缩放后的四个带权重的顶点数据位置和切线,对于法线则是使用上面矩阵的逆矩阵的转置。然后对获得的位置、法线和切线,用权重计算得到经过骨骼平移旋转缩放后的实际的顶点信息。在通常的渲染过程中,上述操作是在CPU中进行的,最后把顶点数据传递给GPU中进行渲染。在顶点数较多且主要是矩阵运算的情况下,CPU进行蒙皮的效率就不如高并行的GPU了,因此会考虑到在GPU中进行蒙皮处理。 GPU蒙皮的一些想法 从上面可以看到,要从CPU中传给GPU的数据有以下几种:一是\(M_{bone\localtoobject} * M{bone\_bindpose}\)这样骨骼数个float4x4的矩阵,但是由于其最后一行是(0, 0, 0, 1),在传递时可以简化成骨骼数个float3x4矩阵,这些矩阵每一帧都要传递一次;二是每个顶点对应的骨骼编号和骨骼的权重,骨骼编号用来查询骨骼矩阵中对应的矩阵,是一个整型的数据,骨骼权重是一个[0, 1]的小数,可以用\(BoneIndex + BoneWeight * 0.5\)的方式,把编号和权重结合成一个float的数据,这样每个顶点的骨骼编号和权重数据是一个float4的数据,可以保存在UV中,也可以用数组的方式传递给GPU,这些顶点数个float4的数据,只需要传递一次就可以了;再有就是模型本身的顶点位置、法线和切线,这些引擎会自动为我们传递给GPU。 在实际操作中,网上通常找到的方案是把动画保存在一张贴图或者是一个自定义的数据结构中,这里可以直接保存顶点数据,甚至不需要在GPU中做蒙皮的操作,但是随着顶点数增加会占用大量的空间;或者是保存骨骼的变换矩阵,在GPU中进行蒙皮,相对来说储存空间会小很多。然而我认为这两种都不是很好的做GPU skinning的方法,将动画信息保存到贴图或者数据结构中,会很大程度上失去Animator Controller的功能,如两个动作之间的插值、触发事件等,对于动画来说甚至是得不偿失的一种效果。因此,我希望能够保留Animator Controller的特性,实时的把骨骼数据传送给GPU,在GPU中进行蒙皮操作。 GPU蒙皮的操作 我的想法是,先离线从SkinnedMeshRenderer中获得骨骼的ID和权重,然后实时的从Animator Controller对应的骨骼中获取每根骨骼的骨骼矩阵,再统一传给一个普通的MeshRenderer,在GPU中进行蒙皮的操作。这中间有一个小坑,Unity同一个模型的SkinnedMeshRenderer和MeshRenderer,他们虽然都能获取到boneweight和bindpose,但是SkinnedMeshRenderer和MeshRnederer的骨骼的顺序有时候会有一些差异,因此最好的办法是,抛弃这两者的骨骼顺序,用Hierarchy中的骨骼顺序来确定我们传给GPU的boneindex,boneweight和bonematrix是一致的。 这里使用的模型及动作是mixamo的hip hop dancing资源。 BoneMatchInfo.cs 这个脚本的作用是,在离线时把一个GameObjectRoot下的所有SkinnedMeshRenderer和Hierarchy中的骨骼的信息结合起来,保存成一个Asset,用于实时的GPU Skinning。这个Asset包含两部分的信息,一个是BoneMatchNode用于记录Hierarchy骨骼列表中骨骼的名称和其bindpose,另一个是BindIndex用于记录所有SkinnedMeshRenderer的骨骼在Hierarchy骨骼列表中的顺序。 using System.Collections; using System.Collections.Generic; using UnityEngine; using UnityEditor; using System; using System.IO; namespace GPUSkinning { [System.Serializable] public class BoneMatchNode { //[HideInInspector] public string boneName; //在查找位于所有Transfom的位置时,设置并使用boneIndex public int boneIndex = 0; public Matrix4x4 bindPose; public BoneMatchNode(string _boneName) { boneName = _boneName; bindPose = Matrix4x4....